
Utility-Focused LLM Annotation for Retrieval and Retrieval-Augmented Generation
📖 arXiv Paper (Accepted to EMNLP 2025 Main 🎉) | 🤗 Model | 🤗 Dataset | 🛠️ Github |
We explore the use of large language models (LLMs) for annotating document utility in training retrieval and retrieval-augmented generation (RAG) systems, aiming to reduce dependence on costly human annotations. We address the gap between retrieval relevance and generative utility by employing LLMs to annotate document utility. Using the Qwen2.5-32B model and Qwen3-32B, we annotate utility on the MS MARCO dataset and NQ dataset.
📦 Utility-Focused Annotation for IR and RAG Dataset
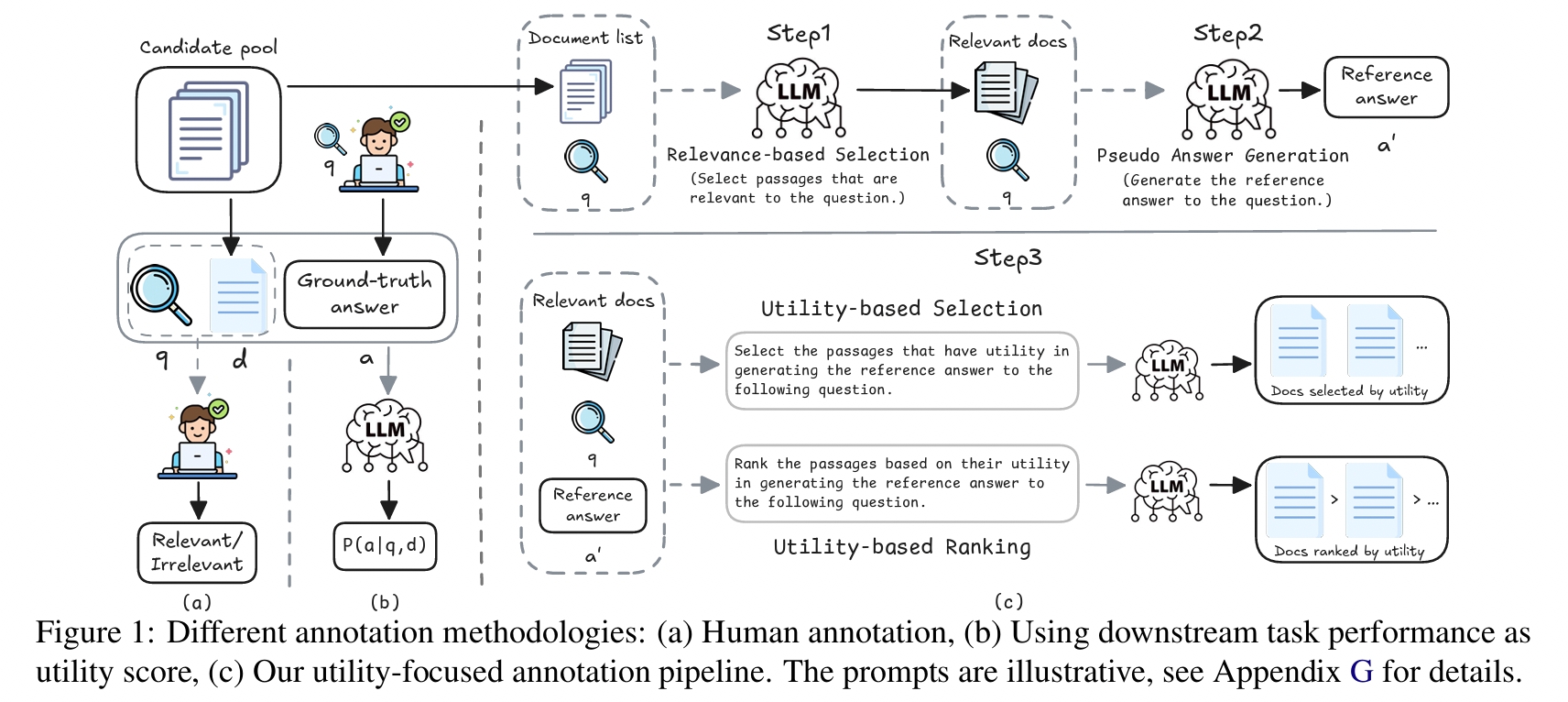
We introduce Utility-Focused Annotation for IR and RAG, a large-scale LLM-annotated retrieval data.
- MS MARCO: About 500K queries
- NQ: About 50K queries.
⭐️ Training
More training deatils are shown in Github. This repository shows different checkpoints trained on different annotation data.
👋 Citation
If you find our paper and code useful in your research, please cite our paper.
@inproceedings{zhang2025utility,
title={Utility-Focused LLM Annotation for Retrieval and Retrieval-Augmented Generation},
author={Zhang, Hengran and Tang, Minghao and Bi, Keping and Guo, Jiafeng and Liu, Shihao and Shi, Daiting and Yin, Dawei and Cheng, Xueqi},
booktitle={Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing},
pages={1683--1702},
year={2025}
}
Model tree for hengranZhang/Utility_focused_annotation
Base model
Shitao/RetroMAE