LeRobot documentation
LIBERO
LIBERO
LIBERO is a benchmark designed to study lifelong robot learning — the idea that robots need to keep learning and adapting with their users over time, not just be pretrained once. It provides a set of standardized manipulation tasks that focus on knowledge transfer: how well a robot can apply what it has already learned to new situations. By evaluating on LIBERO, different algorithms can be compared fairly and researchers can build on each other’s work.
- Paper: Benchmarking Knowledge Transfer for Lifelong Robot Learning
- GitHub: Lifelong-Robot-Learning/LIBERO
- Project website: libero-project.github.io
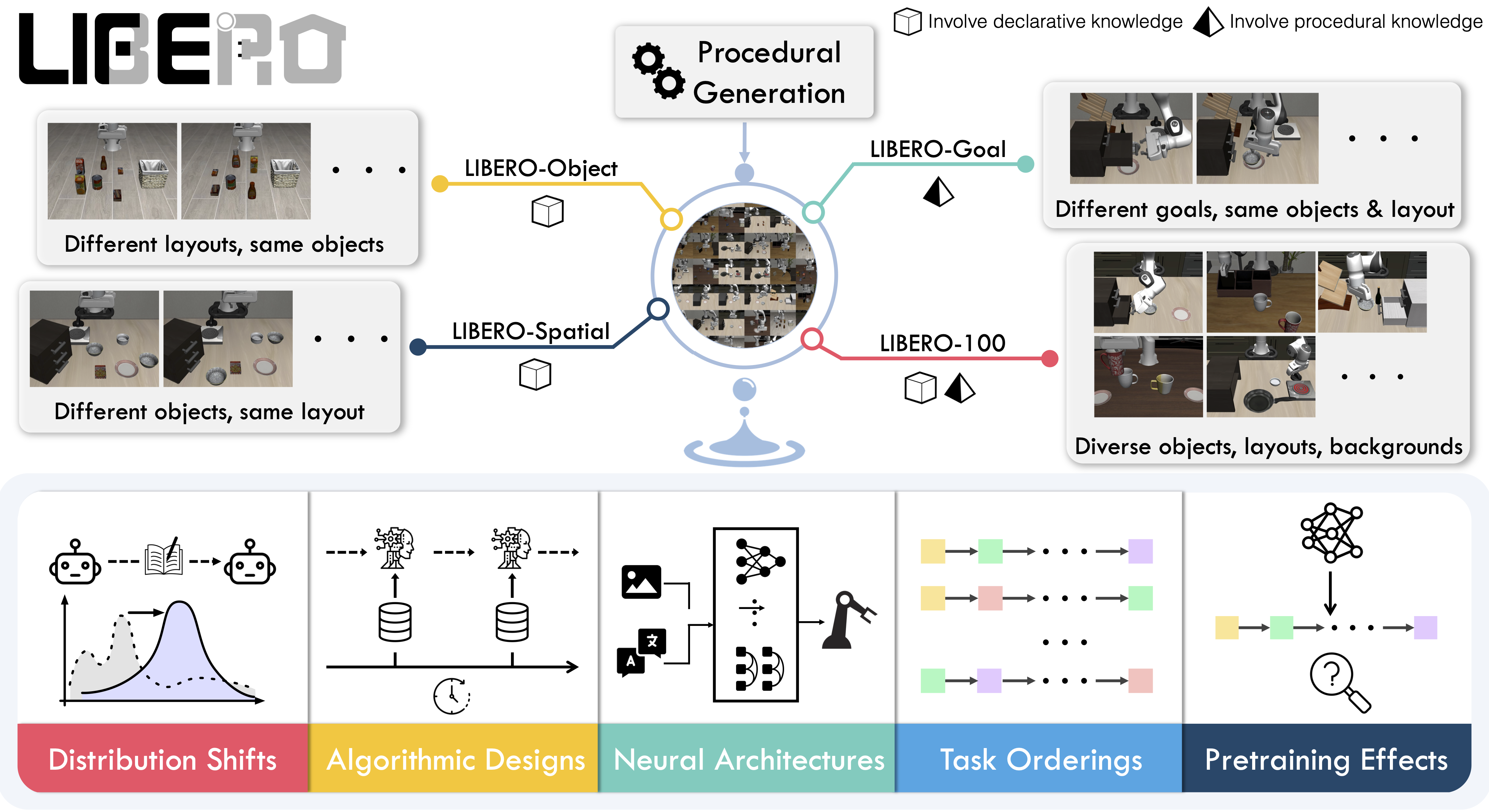
Available tasks
LIBERO includes five task suites covering 130 tasks, ranging from simple object manipulations to complex multi-step scenarios:
| Suite | CLI name | Tasks | Description |
|---|---|---|---|
| LIBERO-Spatial | libero_spatial | 10 | Tasks requiring reasoning about spatial relations |
| LIBERO-Object | libero_object | 10 | Tasks centered on manipulating different objects |
| LIBERO-Goal | libero_goal | 10 | Goal-conditioned tasks with changing targets |
| LIBERO-90 | libero_90 | 90 | Short-horizon tasks from the LIBERO-100 collection |
| LIBERO-Long | libero_10 | 10 | Long-horizon tasks from the LIBERO-100 collection |
Installation
After following the LeRobot installation instructions:
pip install -e ".[libero]"LIBERO requires Linux (`sys_platform == 'linux'`). LeRobot uses MuJoCo for simulation — set the rendering backend before training or evaluation:export MUJOCO_GL=egl # for headless servers (HPC, cloud)
Evaluation
Default evaluation (recommended)
Evaluate across the four standard suites (10 episodes per task):
lerobot-eval \
--policy.path="your-policy-id" \
--env.type=libero \
--env.task=libero_spatial,libero_object,libero_goal,libero_10 \
--eval.batch_size=1 \
--eval.n_episodes=10 \
--env.max_parallel_tasks=1Single-suite evaluation
Evaluate on one LIBERO suite:
lerobot-eval \
--policy.path="your-policy-id" \
--env.type=libero \
--env.task=libero_object \
--eval.batch_size=2 \
--eval.n_episodes=3--env.taskpicks the suite (libero_object,libero_spatial, etc.).--env.task_idsrestricts to specific task indices ([0],[1,2,3], etc.). Omit to run all tasks in the suite.--eval.batch_sizecontrols how many environments run in parallel.--eval.n_episodessets how many episodes to run per task.
Multi-suite evaluation
Benchmark a policy across multiple suites at once by passing a comma-separated list:
lerobot-eval \
--policy.path="your-policy-id" \
--env.type=libero \
--env.task=libero_object,libero_spatial \
--eval.batch_size=1 \
--eval.n_episodes=2Control mode
LIBERO supports two control modes — relative (default) and absolute. Different VLA checkpoints are trained with different action parameterizations, so make sure the mode matches your policy:
--env.control_mode=relative # or "absolute"Policy inputs and outputs
Observations:
observation.state— 8-dim proprioceptive features (eef position, axis-angle orientation, gripper qpos)observation.images.image— main camera view (agentview_image), HWC uint8observation.images.image2— wrist camera view (robot0_eye_in_hand_image), HWC uint8
LeRobot enforces the `.images.*` prefix for visual features. Ensure your policy config `input_features` use the same naming keys, and that your dataset metadata keys follow this convention. If your data contains different keys, you must rename the observations to match what the policy expects, since naming keys are encoded inside the normalization statistics layer.
Actions:
- Continuous control in
Box(-1, 1, shape=(7,))— 6D end-effector delta + 1D gripper
Recommended evaluation episodes
For reproducible benchmarking, use 10 episodes per task across all four standard suites (Spatial, Object, Goal, Long). This gives 400 total episodes and matches the protocol used for published results.
Training
Dataset
We provide a preprocessed LIBERO dataset fully compatible with LeRobot:
For reference, the original dataset published by Physical Intelligence:
Example training command
lerobot-train \
--policy.type=smolvla \
--policy.repo_id=${HF_USER}/libero-test \
--policy.load_vlm_weights=true \
--dataset.repo_id=HuggingFaceVLA/libero \
--env.type=libero \
--env.task=libero_10 \
--output_dir=./outputs/ \
--steps=100000 \
--batch_size=4 \
--eval.batch_size=1 \
--eval.n_episodes=1 \
--eval_freq=1000Reproducing published results
We reproduce the results of Pi0.5 on the LIBERO benchmark. We take the Physical Intelligence LIBERO base model (pi05_libero) and finetune for an additional 6k steps in bfloat16, with batch size of 256 on 8 H100 GPUs using the HuggingFace LIBERO dataset.
The finetuned model: lerobot/pi05_libero_finetuned
Evaluation command
lerobot-eval \ --output_dir=./eval_logs/ \ --env.type=libero \ --env.task=libero_spatial,libero_object,libero_goal,libero_10 \ --eval.batch_size=1 \ --eval.n_episodes=10 \ --policy.path=pi05_libero_finetuned \ --policy.n_action_steps=10 \ --env.max_parallel_tasks=1
We set n_action_steps=10, matching the original OpenPI implementation.
Results
| Model | LIBERO Spatial | LIBERO Object | LIBERO Goal | LIBERO 10 | Average |
|---|---|---|---|---|---|
| Pi0.5 (LeRobot) | 97.0 | 99.0 | 98.0 | 96.0 | 97.5 |
These results are consistent with the original results reported by Physical Intelligence:
| Model | LIBERO Spatial | LIBERO Object | LIBERO Goal | LIBERO 10 | Average |
|---|---|---|---|---|---|
| Pi0.5 (OpenPI) | 98.8 | 98.2 | 98.0 | 92.4 | 96.85 |