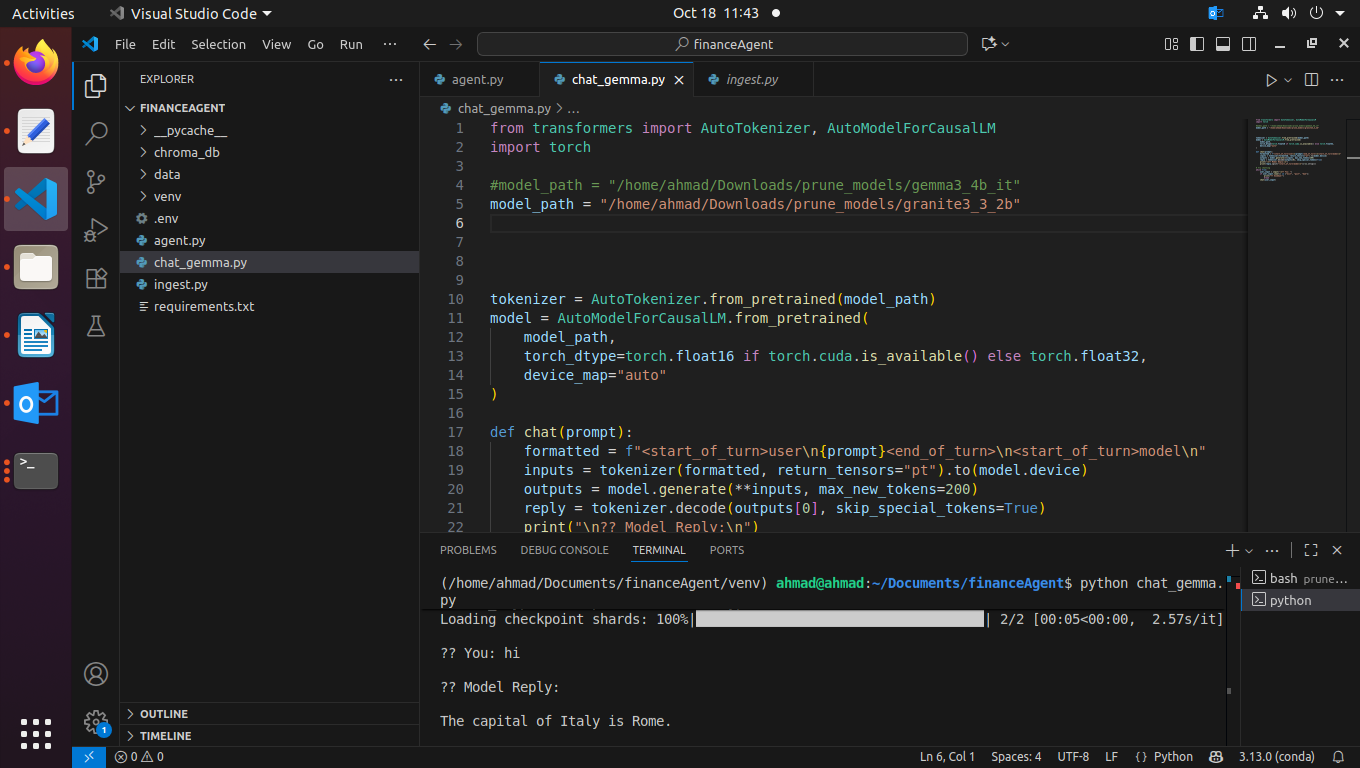
Probably the repo_id format is wrong… Also, since many GGUF models aren’t gated, it’s faster to search for them directly.
A) What’s available right now
- Mistral 7B: public.
Use mistralai/Mistral-7B-v0.3 (base) or mistralai/Mistral-7B-Instruct-v0.3 (chat). (Hugging Face)
- “LLaMA 3B”: this is Llama-3.2-3B from Meta. It is gated.
Use meta-llama/Llama-3.2-3B or meta-llama/Llama-3.2-3B-Instruct. (Hugging Face)
Why you saw 404s:
-
Wrong or incomplete repo ID (IDs are
owner/repo, case-sensitive). (Hugging Face Forums) -
Repo is private or gated and you’re not approved yet. HF returns 404 in that case. (Hugging Face)
B) How to request access for gated models (e.g., Llama 3.2)
-
Open the model page while logged in and click Request/Accept access. (Hugging Face)
-
Gated access is controlled on the Hub; owners can require acceptance and review. (Hugging Face)
C) Minimal commands that work
Authenticate and verify:
# login
hf auth login # or: huggingface-cli login
# verify
hf auth whoami # or: huggingface-cli whoami
Download models:
# Public Mistral 7B Instruct
hf download mistralai/Mistral-7B-Instruct-v0.3 --local-dir ./mistral-7b-instruct
# Public Mistral 7B base
hf download mistralai/Mistral-7B-v0.3 --local-dir ./mistral-7b-base
# Gated Llama 3.2 3B (accept license on the repo page first)
hf download meta-llama/Llama-3.2-3B-Instruct --local-dir ./llama-3.2-3b-instruct
Python alternative:
from huggingface_hub import snapshot_download
snapshot_download("mistralai/Mistral-7B-Instruct-v0.3", local_dir="./mistral-7b-instruct")
D) CPU-only? Use GGUF + llama.cpp
This avoids big PyTorch installs and runs fully on CPU.
Install llama.cpp and run a GGUF directly from HF:
# build
git clone https://github.com/ggml-org/llama.cpp && cd llama.cpp
cmake -B build && cmake --build build --config Release
# run a GGUF in one line (example: Llama-3.2-3B Instruct, quantized)
./build/bin/llama-cli -hf bartowski/Llama-3.2-3B-Instruct-GGUF:Q4_K_M -p "Hello"
You can replace the -hf target with any GGUF repo:file. (GitHub)
E) Good, small, public CPU models (ready today)
-
Phi-3 Mini 4K Instruct (3.8B). Also has an official GGUF repo. (Hugging Face)
-
Qwen2.5-3B-Instruct (3B). Strong small model. (Hugging Face)
-
SmolLM3-3B. Fully open 3B; ONNX and GGUF variants exist from the community. (Hugging Face)
-
TinyLlama-1.1B-Chat GGUF, for very low-resource CPU. (Hugging Face)
-
Zephyr-7B-beta GGUF, if you want a 7B chat model and can tolerate slower CPU speed. (Hugging Face)
F) Quick 404 checklist
-
Always use the exact
owner/repoID, correct casing. (Hugging Face Forums) -
Open the repo page in your browser to confirm visibility or gating. (Hugging Face)
-
Stay authenticated before downloading (
hf auth whoami). (Hugging Face) -
If it’s truly private, owners must grant you access; otherwise you’ll keep seeing 404. (Hugging Face Forums)
G) Note on Python 3.13
3.13 support is improving, but some stacks still lag. PyTorch now lists 3.13 support on its install page, yet issues around dependencies have existed; if you hit install errors, use Python 3.12. (PyTorch)
Short “do this now” script (Ubuntu, CPU)
# 1) Auth
pipx install huggingface_hub || pip install -U huggingface_hub
hf auth login && hf auth whoami
# 2) Download public Mistral 7B Instruct
hf download mistralai/Mistral-7B-Instruct-v0.3 --local-dir ./mistral-7b-instruct
# 3) If you want Llama-3.2-3B, accept access in browser, then:
hf download meta-llama/Llama-3.2-3B-Instruct --local-dir ./llama-3.2-3b-instruct
# 4) CPU inference via llama.cpp + GGUF
git clone https://github.com/ggml-org/llama.cpp && cd llama.cpp
cmake -B build && cmake --build build --config Release
./build/bin/llama-cli -hf microsoft/Phi-3-mini-4k-instruct-gguf:Q4_K_M -p "Hello"
Curated references
-
Model cards: Mistral-7B v0.3, Mistral-7B-Instruct-v0.3, Llama-3.2-3B. Useful to verify availability and licenses. (Hugging Face)
-
HF docs:
hf download, downloads API, gated-model rules. Practical CLI and why 404 appears for private/gated. (Hugging Face) -
llama.cpp: repo and GGUF-on-HF usage page. CPU-first, simple runs with
-hf. (GitHub) -
Alternative small models: Phi-3 Mini 4K, Qwen2.5-3B, SmolLM3-3B, TinyLlama, Zephyr-7B. Good CPU options. (Hugging Face)